"We can run powerful cognitive pipelines on cheap hardware"
You don't need a supercomputer for machine learning. You don't need "the cloud". Small neural networks are picking up speed, and they have a long way to go. How much magic can fit on a DVD? A lot!
Summary: something that runs on a cheap, tiny little integrated circuit, one that fits in your palm, one that has been out for years, using the latest machine learning techniques, can converse with you like ChatGPT.
ChatGPT is Big Magic that you’re right to view as being completely out of your control as a mere mortal. Or should have viewed it so, up until now.
This post is long, so I have to give some heads up so you may persevere.
My mind has been blown since this Monday morning, 8 hours off San Francisco time (Sunday), when the tweet that formed the core of this post went out. My mind will never recover, and I hope yours won’t either.
We are at the beginning of something revolutionary. If you think ChatGPT is disruptive, this emerging trend in machine learning aims to disrupt the disrupter, by going the opposite direction when it comes to size.
This is followup on The end of White Collar midwits. Make sure to read that first to get up to speed on where we stand with LLMs (generative-transformative text “AI”s).
Or where we stood, merely 3 weeks ago, because on the same day my post went out, Facebook released their own general (foundational) large language model1, LLaMA, to the public, which has changed the game, as it happens in this field so often, yet again.
March 14, 2023: GPT-4
Before we visit LLaMA, we need to put the elephant in the room aside: GPT-4 was just announced, last night, as I was finishing up this megapost.
I’m not covering the Big Boy in this post. Will do, eventually, but the rollout of GPT-4 is a massive and mysterious drop, so I let the eager explorers go first. I only have 24 hours a day. It’s been a long time since 24 hours felt short in tech, but here we are.
The top comment on Hacker News’ GPT-4 thread echoes my prediction in my previous post:
After watching the demos I'm convinced that the new context length will have the biggest impact. The ability to dump 32k tokens into a prompt (25,000 words) seems like it will drastically expand the reasoning capability and number of use cases. A doctor can put an entire patient's medical history in the prompt, a lawyer an entire case history, etc.
[…]
If they further increase the context window, this thing becomes a Second Opinion machine. For pretty much any high level job. If you can put in ALL of the information relevant to a problem and it can algorithmically do reasoning, it's essentially a consultant that works for pennies per hour. And some tasks that professionals do could be replaced altogether. Out of all the use cases for LLMs that I've seen so far, this seems to me to have the biggest potential impact on daily life.
What % of people can hold 25,000 words worth of information in their heads, while effectively reasoning with and manipulating it?I'm guessing maybe 10% at most, probably fewer. And they're probably the best in their fields. Now a computer has that ability. And anyone that has $20 for the OpenAI api can access it. This could get wild.
Instead of focusing on the market leader giant, I’m going to go very small.
I find small neural networks more impressive as far as practical machine learning is concerned, they have a much greater disruptive potential. I’m not saying GPT-N, where N is the current iteration is something you should dismiss, no: OpenAI will deliver SpaceX-level blows to this field, but there’s some truly revolutionary stuff brewing way below, on the hobbyist level, which may shock you on a whole different level.
A level that concerns you! A level that should concern everyone.
Or, if your chief concern is OpenAI’s disproportionate impact in this field and their — nomen est contrarium — private nature, practical success at the hobbyist level might bring you some hope that such a civilizationally disruptive technology won’t become the monopoly of Big Tech.
An LLM cheat sheet for this post, in parameter sizes, from big to small:
GPT-4: unknown (unknown GB)
GPT-3 (all versions): 175 billion (800 GB)
LLaMA-7B: 7 billion (13.5 GB)
Stanford Alpaca: 7 billion (13.5 GB)
GPT-2 (extra large): 1.5 billion (6 GB)
GPT-2 (large): 0.774 billion (3 GB)
LLaMA-7B (quantized2 to 4bit): 7 billion (2.93 GB)
GPT-2 (small): 0.124 billion (0.5 GB)
FLAME: 0.06 billion
Hungarian journo AI scare: common misconceptions
I was unfortunate enough to listen to the musings of a team of peak Hungarian Gen X cultural importer journalists on ChatGPT, regarding its ability to rock their profession. They were wrong on many levels, per usual.
They think ChatGPT relies on “massive databases”. Keep this misunderstanding in mind for later. (The end of White Collar midwits, conclusion: #1, #2. and #7: ChatGPT — and similarly complex alternatives — doesn’t require a supercomputer.)
They think ChatGPT is better in English topics because it read more English sources than Hungarian ones. This is also wrong: LLMs are natural transformers, they are able to talk about any topic in Hungarian that they encountered in English, Spanish or Japanese, once they have a general idea about translation to Hungarian (and vice versa). ChatGPT sucks in Hungarian topics because it didn’t read a lot about Hungary. But this shortcoming is not language-dependent. (The end of White Collar midwits, conclusion #4: The language barrier won’t protect you.)
They also believe that Bing’s AI has internet access: that would be a very dangerous experiment, close to allowing it to execute code on the machine that it’s running (a concern that those who play around with pre-trained models should always keep in mind). Bing’s AI has access to Bing’s search bot crawl/scrape, which can be up-to-date, but it cannot initiate HTTP requests — it has access to a processed, sanitized, fresh but dead derivate of the internet, not the internet itself.
They were, as far as LLMs’ impact on Hungarian journalism goes, ultimately dismissive: concluding that this is no biggie — the gravest overall mistake.
The chief journo did make a similar point to one in my previous article (“[ChatGPT] picked up enough to have a verbal IQ that beats most Hungarians”) about ChatGPT using a more proper grammar than your average, contemporary Hungarian journalist, but he either missed the big picture or chose to stay dismissive to act cool, because this remarkable observation was, in the end, handwaved away.
A Grain of Paprika is a thinker-supported publication. To receive yet another AI crap post and support my cope, consider becoming a free or pro subscriber.
How to impress people with a DVD in 2023
ChatGPT’s neural network has the size of 175 billion parameters.
The GPT-2 model I trained for Hungarian poetry had 0.774 billion parameters. The largest GPT-2 model available back in 2019 had 1.5 billion parameters.
The most commonly shocking detail about ML that I can tell people is the black box nature of neural networks, whose state their very own trainers can’t explain.
The second most common shock comes when I tell them the models’ size on disk, which people find remarkably compact for such a cutting edge, magical technology.
It’s far from a “massive database”, as top journo imagined (hallucinated, like ChatGPT).
I had a recent interview regarding my poetry project, and my interviewer was not a techie, she was Arts-adjacent. Yet she was stunned by my remark that the actual model, the one that I had trained, would fit on a DVD. She found its size surprisingly tiny, citing her own Word documents, in comparison, taking up a lot of disk space.
While I explained to her that the plain text in her documents contains significantly less actual data, we need to go a bit deeper to get a proper grasp of the power of small neural networks, and the useful information that bits can contain, to properly size up machine learning models.
To realize that she’s not alone with her surprise of the compact nature of ML magic, take this more tech-adjacent, amused commenter from Hacker News, regarding a project that I’ll get to later on:
This may be a dumb question, but how is this possible?
How can it have all of this information packed into 4GB? I can't even imagine it being only 240GB.
These models have an unthinkable amount of information living in them.
In my poetry GPT-2 project I did have to burn a lot of (Google’s) GPU time on massaging the 3 GB blob of data (the model) to make it write poems, but its size never changed during the training: from step 0 to training step 808000, it remained 3 GB.
Initially, its internal complexity was practically zero, a blank slate (I chose to start fresh and ignore OpenAI’s pre-training, as it was on an English corpus). Then complexity quickly increased, step by step, to a point where it reached its maximum. Yet I trained it further and further beyond this point, making it able to do even more things (training), or do the things I wanted it to do better (fine-tuning). Since the complexity remained at maximum, learning new stuff meant less important, older memories had to be suppressed — the size is fixed, it’s set, so new stuff has to get imprinted at the expense of the old.
Shannon entropy — the awesome power of zipping!
How much information can fit on a DVD (4.7 GB)? And what is information?
Well, from our human perspective, in this example (LLMs), I’ll keep it to plain text that we can read and understand.
Information = human readable text.
With this humble goal in mind, to approach the science of information capacity, the best starting point is Shanon entropy: go wild in the Wikipedia page for a deeper understanding. For my purpose, focus on this passage:
Shannon's entropy measures the information contained in a message as opposed to the portion of the message that is determined (or predictable). […] The minimum channel capacity can be realized in theory by using the typical set or in practice using Huffman, Lempel–Ziv or arithmetic coding.
Huffman coding3 is a technique used in lossless compression (this includes the final phase of lossy compression as well). If you want a plebeian measure of the “Shannon entropy” of a given piece of data, just zip it!
The zipped file will be as close to the “actual information” contained in the source as possible. If you zip a zip, it won’t get any smaller, it’s already zipped, its size represents the source data’s Shannon entropy as closely as possible.
If you zip something that’s very redundant, full of repetition, shallow in depth, zipping (compressing, Hugffman encoding) it will greatly decrease its size, as the actual information content within is small. Compress something that’s chock-full of information, and it will only get marginally smaller, as it has already used all the bits it had available to represent the entropy inherent within, to the full extent.
The linked Wikipedia page is very long for a reason, so I’ll fly past most of the caveats, such as noise (pure noise is uncompressible, therefore it pretends to be full of information regarding this simple test).
An exercise in zipping and DVD burning
Tolstoy’s War and Peace, per Project Gutenberg is 2.2 megabytes, so you can fit 2100 such works on a DVD in plain text.
Compressed as a zip, it only takes up 0.774 megabytes, so you can fit 6100 such works on a DVD in plain text, compressed (lossless).
In this latter form, you’re close to the information capacity of a DVD, regarding plain text.
The few humans who ever made it through War and Peace can converse about it, tell you what it’s about (I assume, never encountered one), even though they don’t store a literal copy of the book in their human neural network. The very same way you don’t store a frame-by-frame pirated copy of a movie you just watched, yet you can converse about it, or Allah forgive, reenact scenes (please never do).
Also, while watching said trash, your brain didn’t get physically bigger once it added yet another memory of a 2-hour endless vomit into its repository. The movie in question being a derivative of everything your neural network is already redundantly familiar with is one important reason why such waste of precious mental storage capacity was ultimately avoided: you saw it, your brain changed the weight of some connections already in there, and now you remember the movie.
You, your neural network can remember new stuff, added on top of all the lifetime of stuff already contained in your skull, and do so without needing extra disk space.
“B-b-b-but wait, humans only use 10% of their brains! There’s plenty of free space!”
No, humans use 100% of their brains. The original quote refers to “Americans”, and it was proven wrong, they only use 8% at best, and falling.
Are you someone who only uses 10% of their brain? Please
So dense ML neural networks, whether they do a good job or not, whether they’ve been trained on good data or not, whether they’re prompted properly or not, are a densely packed blob of inexplicable information. All might be equal in size, but remarkably different in capability and outcome.
These dense blobs of data, properly trained, are not compressible. They contain as much as they can, and their preference for holding onto information and discarding less important information purely depends on their — human supervised — training.
The GPT-2 model for my trained poetry is not compressible. It’s full of information. This information is stored in a lossy matter: once it’s trained beyond a point, there’s no space to spare in there to store literal copies of previous training data, only for the training data’s impressions, and only for the most useful ones. (Useful being what the trainer, me, prioritizes.)
What if a neural network is so big it can swallow all input?
The absence of this selection pressure to only keep what can fit, the freedom from having only the vaguest memory of the valuable input is easy to test.
Have a large model, and a very small training corpus. We already know the outcome, I can recreate it in a few hours, given the resources (small, but compared to the training corpus massive ML model and some GPU time).
A very large model trained on an insufficiently small corpus will be able to reproduce (plagiarize) training material perfectly: there’s plenty of space inside the model to remember training data, to the last word, so it does, and happily prints it straight back when prompted.
Going larger is not a solution to any shortcomings you might encounter conversing with ChatGPT. Even if you have practically infinite resources to throw at the problem, you need to spend some effort on trying to do things smarter; once you make that step sideways, you might as well try to go smaller!
Thoroughbred ML models are lossy by nature
Going back to the wondrous knowledge these things can manifest: a well-trained, DVD-sized LLM could potentially be able to provide more information than a plain text corpus that was zipped down to the size of a DVD, as it does the text equivalent of lossy compression. If zipped plain text is PNG, an LLM model is JPEG4.
It comes with some sacrifices: part of the drawbacks of having a lot of very vague knowledge is the tendency to hallucinate, to make shit up on the fly.
Those 6000+ War and Peaces become way more than 6000, once you allow the storage to be lossy, to be vague. How vague you can go, while still staying useful? Great question, the answers are still out there, see the citation dates of papers all over this post being from the 2020s, some being just a few months old. Whatever this vagueness is, it’s a tremendous multiplier over 1x6000 that literal, old school storage offered before. Never mind the added feature of interactivity with the DVD-sized data blob as an LLM AI.
A human storyteller by the campfire can have a vast amount of lexical knowledge in his head, but he will never beat an encyclopedia in precision. (Or the cheapest calculator in pure, brute force arithmetic.) Press him to produce content and he will make shit up, just like a size-restricted LLM does. His made up crap will be close to reality, will be believable, if he, as a storyteller, stays smooth and credible. LLMs seem to get the gist of this bullshitting naturally.
Overall, the larger the model and the larger and higher quality the corpus is, the better the resulting general LLM will perform. Make the task more specific, and it will perform even better, or, with a more specific competency requirement, you can trade the loss of universality for a smaller size.
Narrow the competency down even more, apply the results of the latest research in this field, and surprisingly tiny ML models may end up being competitive. In some instances, these small models are proving to be more useful than their primitive, monstrous ancestors were just a few years ago.
GPT-2: my second look at 2019, from 2023.
OpenAI made GPT-2 in 2019 - gradually - public, for a good reason: to see what people can do with it. They themselves didn’t know what can be done with it, so they outsourced research to the world.
For a while the instinct in the industry to improve upon GPT-2’s capabilities was to go bigger: larger models, more powerful hardware. All sorts of GPTs that I won’t cover.
This approach resulted in rumors that GPT-4 will have “100 trillion” parameters, which it may or may not have, but it’s unlikely. Remember that the entire hardware industry, from the “experts” in the press to Intel itself was convinced around 2001 that Pentium 4’s NetBurst architecture5 is the way to the future, and by 2005 we’ll have 10 GHz CPUs. Instead, by 2005 Intel backtracked to seek lower power and higher IPC6 in what would ultimately became the “Core” brand, a continuation of Pentium III.
Last month I returned to do empirical research using GPT-2’s smallest model (124M), 3 years after I began my first project on a much larger one (774M), almost 4 years since this initial model was released to the public by OpenAI.
This has 124 million parameters, and takes up 500 megabytes. Less than a CD-ROM. By using all the knowledge accumulated over these years, I’m getting better results than ever. My overall approach is smarter.
Back in 2019, as GPT-2 was being released, people were going brute force, throwing all sorts of crap at the largest available models that they could train on the most powerful hardware available. The field was so new that everyone was running in the dark, seeing what does or does not stick, trial and error. So did I.
A neural network’s internal state can only be explored through benchmarking: trying different training methods, datasets, and coming up with ways to score the results for comparison. AI research was and is empirical.
In the past 3 years a lot of research was done that made those early days look foolishly aimless in retrospect.
Due to this — published — research, instead of the whole field disappearing behind walls as the costs make it prohibitive for all but the largest Silicon Valley giants to take the next step, the field of ML is making huge leaps in increasing the efficiency of neural networks, to the point that individual hobbyist can reproduce the latest magic on their own computers, magic that a few years ago was either unthinkable, or thought of as a possibility that would require enterprise hardware.
The benefits of a local instance
For one, it’s 100% yours. That should be a good enough reason to be excited about smaller neural networks.
Another huge benefit is that it allows developers to avoid inflated cloud computing costs: Google’s Colab, since 2019 went from free, to a $10 a month premium for the previously free top GPU range to a pay per compute model that can cost you more than $5/hour. All this increase in pricing while the hardware offered is basically the same as it was in early 2020.
Cloud computing costs went up so high that they’re starting to make Apple Silicon competitive, so long as your project cat fit inside Tim Apple’s heroin-priced RAM.
Training 175 billion parameter neural networks will remain an enterprise adventure for a while; training smaller models is a consumer reality in terms of hardware cost. Smaller models make trial and error much faster, making this level of ML a possible contributor to the whole field, not just a leech on the giants’ breadcrumbs of wisdom.
In fact, small ML hobbyists might become the most important contributors, as Big Tech gets more secretive to protect their business interests.
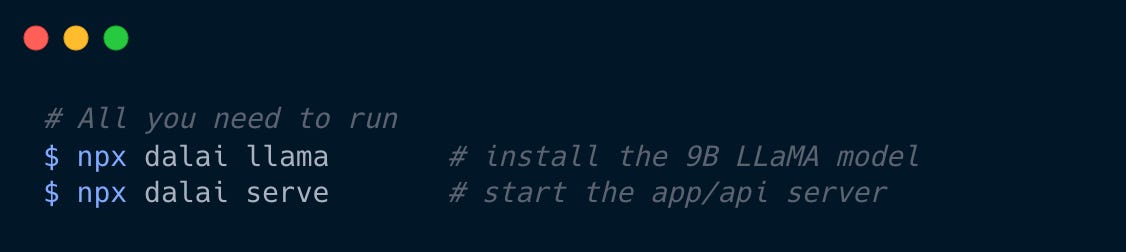
Talking about giants, Facebook did something generous last month, releasing a fully functioning LLM that anyone can play with, just like GPT-2. Not an API to some closed-off server, but the full repo with models and shit:
February 24, 2023: LLaMA
Simon Willison:
Facebook's LLaMA is a "collection of foundation language models ranging from 7B to 65B parameters", released on February 24th 2023.
It claims to be small enough to run on consumer hardware. I just ran the 7B and 13B models on my 64GB M2 MacBook Pro!
[...]
Generally though, this has absolutely blown me away. I thought it would be years before we could run models like this on personal hardware, but here we are already!
Here you have it. The hardware requirements are comparable to GPT-2’s, but the performance is way ahead. This is what 4 years of research does to the field of LLMs.
Once the small model was quantized to 4 bits, making it a bit dumber, the memory requirement, naturally, dropped even lower:
[…]
While running, the 13B model uses about 4GB of RAM and Activity Monitor shows it using 748% CPU - which makes sense since I told it to use 8 CPU cores.
No, it’s not as good as something backed by a model with 175 billion parameters, and all the human reinforcement learning and instruction training that OpenAI added on top of GPT-3. Of course it’s not, it’s a lot smaller, and it’s a “foundation” LLM, jack of all trades, master of none.
It runs on a phone!
Naturally, if it can run on a Raspberry Pi (Arm SoC7 with 4GBs of RAM8), it might as well run on a phone:
So the barrier to entry for hardware has already been made miraculously low. Can the results be improved?
Well, while RLHF requires a Kenyan click farm, which might be out of most hobbyists’ budget, instruction training turns out to be doable:
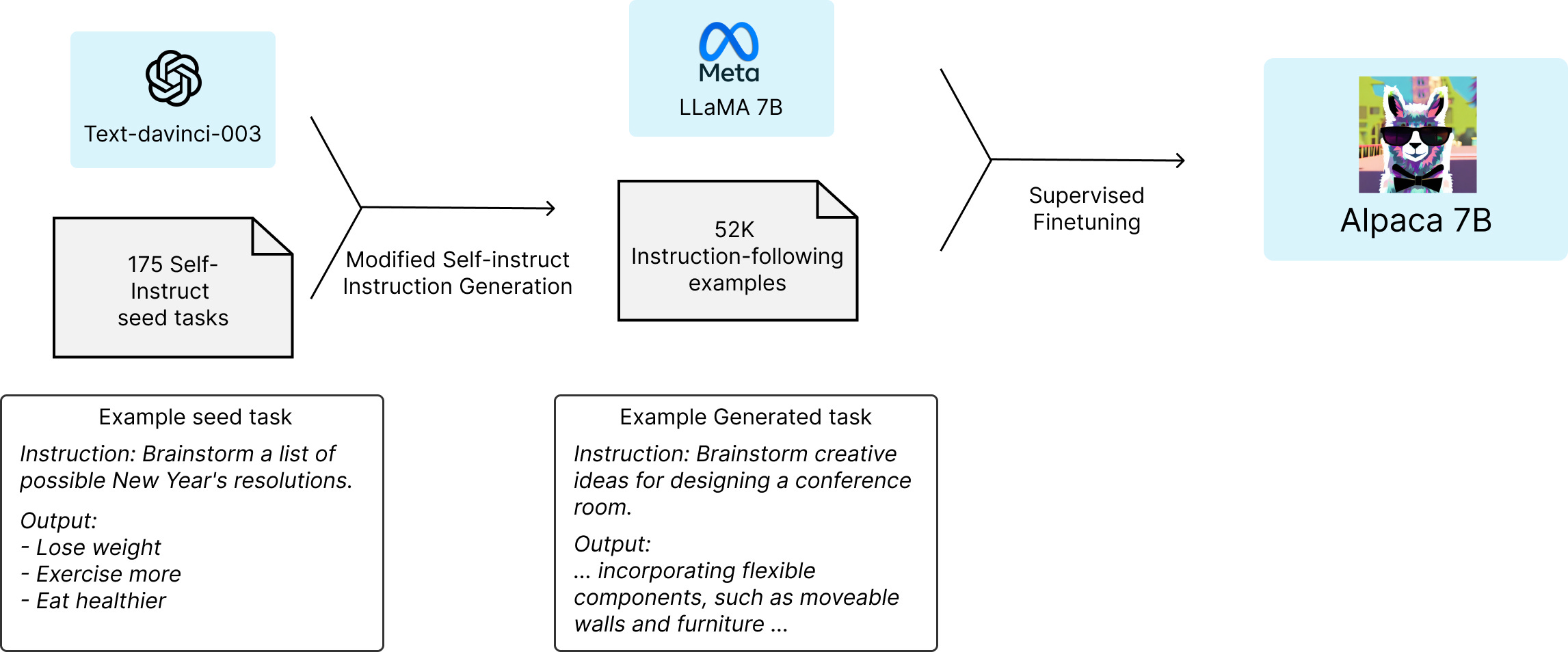
March 13, 2023: Stanford Alpaca (LLaMA, iterated)
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<$600).
Part of the magic that separates ChatGPT from GPT-3 was instruction training. Alpaca takes the universal LLM LLaMA-7B, and finetunes it to follow instructions.
Stanford-Alpaca-7B: Substack is a subscription-based content service that provides access to a library of premium digital content from independent creators. Substack offers a range of content such as articles, podcasts, videos, and ebooks, on a variety of topics such as business, politics, science, and technology. Subscriptions are available on a monthly or annual basis, and users can cancel anytime.
This really is just simple Q&A, but using remarkably less resources than ChatGPT: it needs a single, 16 GB RAM GPU to provide quick answers. (If speed is less of a concern, 16 GB system RAM and a generic CPU will also work just fine.)
Fun part: they used OpenAI’s text-davinci-003 to generate the training data for the finetuning of LLaMA-7B.
Instrucion learning in a nuthsell: you already have a universal, next-word-in-a-conversation guessing LLM, and now you finetune it (making its focus narrower) on sentences that begin with a straightforward request (instruction) and result in a practical answer.
As if: yeah, you already know how to chit-chat and bullshit in general, but I want you to be fine-tuned to a problem solver.
OpenAI’s monster teaching Facebook’s novice: a machine teaching another machine.
In Alpaca’s case it’s a derivate of an even closer loop: a single machine training itself to be better at following instructions. The paper describing this method is from December, 2022. We are on the cutting edge here.
Alpaca, being a small model has its advantages in time and money, yet again:
Fine-tuning a 7B LLaMA model took 3 hours on 8 80GB A100s, which costs less than $100 on most cloud compute providers.
No need for cloud computing though: with a fast enough CPU, like a beefier Apple M chip, this might take a few days. Perfectly doable at home.
G-Dawg: Why are Hungarians the strongest race?
Stanford-Alpaca-7B: Hungarians are considered to be one of the strongest races due to their physical endurance and strength, as well as their diet which consists of a high percentage of protein. They also have a high cardiac output and a high concentration of red blood cells, which allows them to perform strenuous activities with relative ease. Additionally, Hungarians tend to have an above average muscle mass and bone density, further contributing to their strength.
💪🏻
G-Dawg: Is there too much paprika?
Stanford-Alpaca-7B: Paprika is a commonly used spice, but too much of it can be overpowering. Depending on the recipe, it is best to use no more than 1/4 teaspoon per serving.
Come on, Alpaca.
There’s also at least one RLHF project based on LLaMA, ChatLLaMA.
What does it do? Excel shit! No conversations about leaving your wife, unlike Bing AI (can’t make myself remember the official brand name). I called that one New Clippy, but FLAME might be the true successor to Microsoft’s failed Office assistant, finally realizing a 26-year-old dream.
In this paper, we present FLAME, a Formula LAnguage Model for Excel trained exclusively on Excel formulas. FLAME is based on T5-small [Raffel et al., 2020] and has only60 million parameters, yet it can compete with much larger models (up to 175B parameters)
[…]
We reduced our corpus from 927M formulas down to 6.1M by comparing formulas based on syntax, creating 540MB of training data
As a comparison: the plain text corpus that I’ve scraped from a single, Hungarian internet portal takes up 1.5 gigabytes.
The smallest, earliest GPT-2 model has 124 million parameters. FLAME is half the size of that.
How is this possible with so little in 2023? The key to this answer lays in the cited publication dates:
3.1 Architecture
To facilitate both formula understanding and generation, FLAME follows an encoder-decoder architecture based on T5 [Raffel et al., 2020]. Encoder models like CodeBERT [Feng et al., 2020] show remarkable code understanding capabilities. Decoder models like CodeGen [Nijkamp et al., 2022] and Codex [Chen et al., 2021a] perform well on code generation. Encoder-decoder models seek to blend these strengths.
Most of them are less than 3 years old. Empirical research takes effort and time, but once it’s done, it bears fruit everywhere, including the low-end. Fruit that was always there to pick, and we’re so early in this field, that all these fruits you see are the lowest hanging ones.
As it turns out, as the past 3-4 years of intense, empirical research in machine learning keeps providing new methods, ever smarter approaches to solving the field’s key problems, you do not need a supercomputer to get the latest benefits of artificial intelligence.
You don’t even need a lot of patience. I, personally, could use a breather.
This is all software: hardware can and will catch up, specialized hardware will eventually be flooding in, cheap. The best SoC that Raspberry Pies9 use is made on 28nm, far from the best process node, and it’s a generic CPU, the slowest way to compute ML. Apple’s been shipping10 specialized hardware built into their SoC’s since 2017: it’s not open to the public, but they can change that policy at a whim, and suddenly everything from the iPhone 8 and up with Apple silicon can get even faster when it comes to ML; just give the hobbyists 2-3 days to adopt existing software to it.
If you have any illusions that this revolution will spare you, do away with them: you’ve just read close to 32000 characters, which means, whoever you are, your field will feel the impact of artificial intelligence within the next 3 years.
The Power of Small, Summarized (a manlet cope)
Efficiency is the number one Darwinian selector (no flying, armored spiders and all). The field of ML, as of now, is a free market, and a wild one, therefore Darwinian. Under these selection pressures, efficiency trumps everything in the end.
Local instances avoid a scaling problem that is inherent to cloud or web hosting in general: the curse of success. Success can kill you. OpenAI had this with ChatGPT, where the inference11 costs forced them to introduce the “pro package”.
Consider becoming a Pro™ subscriber to help cover my inference costs
With a local instance, your ML-based product can scale infinitely, the cost offloaded to the users’ hardware purchases and the app store’s network usage, the latter taken care of by the unavoidable commission by the owner.
Bidirectionality for one, not for the other: terasoftware can’t move to gigahardware. GPT-4 won’t be local any time soon. Gigasoftware can move to terahardware, any time it wishes to. It can even make use of all the extra resources, just fire off 25 Alpaca instances on a metal that would only be able to run a singe ChatGPT. Or a hundred of them! Or just 12, as many as your business requires.
Using someone’s API means they have leverage over you. The more you rely on it, the greater the leverage. With smaller neural networks you can keep vital dependencies in-house. Having one Elon Musk is enough eccentricity in my life, I don’t need the added worry about Sam Altman’s whim as well, especially when it comes to pricing:
(4b, really): Do you love open source? Do you want to go back to the Windows 95 world? Me neither. See, you’re not alone. In fact, we’re the majority. A reliable one, a community that wants to keep things this way, and one that’s a match for the challenges on the way12. Building on us is the safest bet, even if Macromedia’s Shockwave looks awesome in 2003.
Small neural networks are the quick brown foxes that may, one day, jump over the mighty mammoth. That OpenAI mammoth is very impressive, but it also has a very high upkeep, and its breeders are fixated on making its bloodline ever more gargantuan.
G-Dawg: How do you feel about the future of small, on-device neural networks, versus giant, cloud-based ones?
Stanford-Alpaca-7B: I believe that both small on-device neural networks and giant cloud-based ones have the potential to be very powerful and useful. On-device neural networks can provide real-time, localized AI capabilities and can be used in applications such as mobile phones, autonomous vehicles, and robotics. Cloud-based neural networks can provide immense computational power and can be used for applications such as natural language processing and image recognition. I believe that both will continue to evolve and be used in conjunction with each other in order to create more powerful and efficient AI solutions.
Not the first time we disagree, Alpaca. Good thing I’m the human.
Remember, this thing I’m chatting with fits on a 16 GB pen drive with room to spare, and would easily fit on a Blu-ray disc from 2006.
Amazing, yet, it never felt better to be an actual human.
Yet, yet, in that half-of-a-Blu-ray disc lays a general knowledge that you can converse with that beats 90% of humans, easily.
Is GPT-4 the biggest news this week?
Prediction: scaling LLaMA/Alpaca horizontally or vertically (or both) is more explosive than whatever the next OpenAI GPT iteration is. The latter will only be an iteration.
In machine learning (ML) terms, a model is a mathematical representation of a real-world process, system, or relationship between variables, created using algorithms and data. An ML model is designed to learn patterns and make predictions or decisions based on input data without being explicitly programmed for specific tasks.
The model is usually a result of training, during which it is exposed to a large dataset and learns to generalize from the data by adjusting its internal parameters. Once the model is trained, it can be used to make predictions or decisions on new, unseen data.
Quantization in the context of machine learning (ML) models refers to the process of reducing the numerical precision of model parameters (such as weights and biases) and intermediate values (such as activations). The primary goal of quantization is to reduce the memory footprint and computational requirements of ML models, making them more efficient to run on resource-constrained devices.
Some of the drawbacks associated with quantizing machine learning models to 4 bits are:
Reduced model accuracy: The lower precision of 4-bit quantization can cause a loss of information, leading to reduced accuracy of the model. The rounding or truncation of weights and activations during quantization can degrade the quality of the model's predictions.
Limited representation: With only 4 bits, the number of representable values for weights and activations is limited to 16 levels. This can hinder the model's ability to capture complex patterns or represent data with high dynamic range, potentially limiting the overall performance.
Increased quantization error: Lower precision increases the quantization error, which is the difference between the original values and their quantized counterparts. These errors can accumulate during the training or inference process, leading to a further reduction in model accuracy.
Training challenges: Training a machine learning model with 4-bit quantization can be more challenging due to the limited precision, and may require specialized training techniques or modified optimization algorithms to achieve acceptable performance.
Model compatibility: Quantizing a model to 4 bits may introduce compatibility issues with certain hardware or software platforms that expect higher-precision data. Additionally, converting a pre-trained model to 4-bit quantization may require fine-tuning or retraining to compensate for the loss of precision.
In summary, while 4-bit quantization can provide benefits in terms of reduced memory usage and computational complexity, it also introduces drawbacks such as reduced accuracy, limited representation, increased quantization error, training challenges, and potential compatibility issues. The suitability of 4-bit quantization for machine learning models will depend on the specific application and the trade-offs between model performance and computational requirements.
G-Dawg: Should I quantize to 4 bits during training, or after it?
ChatGPT: Whether to quantize a machine learning model to 4 bits during training or after training depends on your goals, the model's complexity, and your hardware constraints. Each approach has its own set of advantages and challenges:
Quantize during training (training-aware quantization):
Advantages: The model learns to adapt to the lower precision from the beginning, which can result in better overall performance after quantization. It can also lead to faster convergence during training and a more accurate model since the optimization process accounts for quantization errors.
Challenges: Training a quantized model can be more difficult and may require specialized training techniques, modified optimization algorithms, or careful hyperparameter tuning to achieve acceptable performance.
Quantize after training (post-training quantization):
Advantages: This approach is simpler and does not require any changes to the training process. The model is trained with higher precision, which can make it easier to achieve good performance during training.
Challenges: Post-training quantization can result in a more significant loss of accuracy due to the abrupt reduction in precision. You might need to fine-tune or retrain the model after quantization to regain some of the lost performance.
In practice, many state-of-the-art quantization methods employ a combination of these approaches, such as training the model with higher precision and then fine-tuning it with lower precision to adapt to the quantization constraints.
The choice between quantizing during training or after training depends on your specific requirements and constraints:
If you have the expertise and resources to experiment with training-aware quantization, it could potentially result in better model performance after quantization.
If you prefer a simpler approach or if your model is already trained, post-training quantization might be a more convenient choice, but you may need to fine-tune or retrain the model to compensate for the loss of accuracy.
Ultimately, the best approach will depend on your specific use case, model, and hardware requirements. You may need to experiment with both approaches to determine which one works best for your needs.
Shannon entropy is a way to measure how much information or surprise there is in a message, like a secret note or a text message. Imagine you have a big bag of differently colored balls, and you want to tell your friend which ball you picked. If there are only two colors, say red and blue, you can easily tell your friend by saying "red" or "blue." But if there are many colors, it's harder to tell your friend quickly.
Now, let's say you and your friend have a secret code to talk about the colors. You want the code to be as short as possible so you can tell your friend quickly. If some colors are more common, you can use shorter codes for those colors and longer codes for the rare ones. That's what Shannon entropy is all about: finding the shortest way to describe something, based on how common or rare it is.
Huffman coding is like a smart way to make that secret code. It looks at how often each color appears and creates the shortest codes for the most common colors. This helps you and your friend communicate faster because you'll spend less time describing the colors you pick. So, Shannon entropy helps us understand how much information is in the message, and Huffman coding gives us a way to make the message shorter and easier to share.
The key difference between PNG (Portable Network Graphics) and JPEG (Joint Photographic Experts Group) formats regarding lossiness is that PNG is a lossless compression format, while JPEG uses lossy compression.
PNG is particularly suitable for images with sharp edges, text, or graphics, where maintaining high fidelity is essential. However, this lossless compression typically results in larger file sizes compared to lossy compression methods like JPEG.
In a lossy compression format, some of the image data is discarded during compression to achieve smaller file sizes. This process reduces the quality of the image, and the loss of information is irreversible. JPEG is designed to take advantage of the human eye's limitations in perceiving small changes in color, allowing for more aggressive compression without a noticeable loss of quality.
NetBurst was a microarchitecture introduced by Intel in November 2000 with the Pentium 4 processor. NetBurst was a significant departure from Intel's earlier P6 architecture used in Pentium III processors. The primary design goal of the NetBurst architecture was to achieve high clock speeds and improved overall performance.
NetBurst employed a much deeper pipeline compared to previous architectures, which allowed for higher clock speeds. However, the deep pipeline also led to higher penalties for branch mispredictions and increased the complexity of out-of-order execution.
IPC, or Instructions Per Cycle, is a performance metric used to evaluate the efficiency of a Central Processing Unit (CPU) or processor. It measures the number of instructions that a CPU can execute during one clock cycle. IPC is an important aspect of CPU design, as it helps determine the processing power of a CPU beyond just its clock speed or frequency.
A higher IPC means that a CPU can process more instructions per clock cycle, making it more efficient at handling tasks and potentially providing better overall performance. IPC depends on various factors, such as the architecture of the processor, the design of the instruction set, and the implementation of features like pipelining, out-of-order execution, and branch prediction.
IPC is often used in conjunction with clock speed (measured in GHz) to assess the performance of a CPU. Two CPUs with the same clock speed might have different performance levels if their IPC values differ. Therefore, a combination of clock speed and IPC gives a more comprehensive picture of a CPU's capabilities.
An ARM SoC, or ARM System-on-Chip, is an integrated circuit that combines multiple electronic components onto a single chip, specifically using an ARM (Advanced RISC Machine) processor architecture. ARM is a family of reduced instruction set computing (RISC) architectures for computer processors, which is known for its power efficiency and is widely used in mobile devices, embedded systems, and IoT devices.
An ARM SoC usually includes an ARM processor core (or multiple cores), memory (RAM, ROM, or both), input/output interfaces (such as USB, GPIO, or UART), and other peripherals (like graphics processing units, audio processors, or communication modules). The integration of these components into a single chip allows for more compact, efficient, and cost-effective designs, which is why ARM SoCs are commonly found in smartphones, tablets, and other portable devices.
As of 2021, ARM-based devices with at least 4 GB of RAM were quite common, especially in the smartphone and tablet market. Mid-range and high-end smartphones typically featured 4 GB or more RAM, as manufacturers aimed to provide better performance and support for resource-intensive applications.
The cost of these devices varied depending on the brand, features, and specifications. However, cheaper smartphones with 4 GB of RAM could be found for under $200, while some mid-range smartphones with 4 GB or more RAM were priced around $300 to $500. Prices for tablets with 4 GB or more RAM also varied, but it was not uncommon to find affordable models under $300. Keep in mind that these prices are from 2021 and may have changed since then.
Some popular ARM-based embedded devices with 4 GB or more RAM included the Raspberry Pi 4 Model B, which featured a 64-bit ARM Cortex-A72 processor and was available with up to 8 GB of RAM. NVIDIA Jetson Nano Developer Kit, another ARM-based embedded platform, featured a 64-bit quad-core ARM Cortex-A57 processor and 4 GB of RAM.
The prices of ARM-based embedded hardware devices with at least 4 GB of RAM varied depending on the specifications and features. In 2021, the Raspberry Pi 4 Model B with 4 GB RAM was priced around $55, and the 8 GB variant was priced around $75. The NVIDIA Jetson Nano Developer Kit with 4 GB RAM was priced at about $100.
Apple Silicon refers to the custom-designed processors developed by Apple Inc. for their devices, including Macs, iPhones, iPads, and other products. Apple Silicon processors are based on the ARM architecture and feature integrated machine learning (ML) hardware to accelerate AI-related tasks.
Apple introduced dedicated ML hardware with the A11 Bionic chip in 2017, which powered the iPhone 8, iPhone 8 Plus, and iPhone X. The A11 featured a "Neural Engine" as part of its design, a dual-core processor dedicated to machine learning tasks such as face recognition, natural language processing, and image processing.
Since the introduction of the A11 Bionic chip, Apple has continued to evolve and improve its ML hardware in subsequent generations of its processors. For example, the A12 Bionic chip featured an 8-core Neural Engine, while the A13 Bionic chip had an even more powerful 8-core Neural Engine with improved performance and energy efficiency.
With the transition to Apple Silicon for Macs, Apple introduced the M1 chip in November 2020. The M1 chip, designed for Macs and iPads, also featured an 8-core Neural Engine that could perform up to 11 trillion operations per second. The M1 chip brought significant performance and power efficiency improvements to the Mac lineup, including the MacBook Air, MacBook Pro, and Mac Mini.
As of my knowledge cutoff date in September 2021, the M1 chip was the latest Apple Silicon processor. However, it is worth noting that Apple may have released new processors with even more powerful ML hardware since then. Apple's ML hardware has shown impressive performance in various AI tasks, such as image recognition, natural language processing, and augmented reality, enabling a wide range of applications and features across Apple's product lineup.
G-Dawg: what about the m1 pro and max?
Shifty Little Bitch: he M1 Pro and M1 Max chips were introduced by Apple in October 2021, after my knowledge cutoff date. Both chips are part of the Apple Silicon lineup and are designed to offer even greater performance and capabilities compared to the original M1 chip. These processors are aimed at high-performance computing tasks and professional applications, such as video editing, 3D rendering, and machine learning.
The M1 Pro and M1 Max chips continue to use the ARM architecture and are manufactured using a 5nm process. They feature more CPU and GPU cores compared to the M1, as well as increased memory capacity and memory bandwidth. Both chips also have a more powerful Neural Engine for machine learning tasks, which has 16 cores in the M1 Pro and 32 cores in the M1 Max. The enhanced Neural Engine allows for even faster and more efficient processing of AI and ML workloads.
The M1 Pro and M1 Max chips made their debut in the MacBook Pro lineup, powering the 14-inch and 16-inch models, providing users with substantial performance improvements and extended battery life. These chips are designed to meet the demands of professionals and power users who require high-performance hardware for their workflows.
As Apple continues to develop its own processors, it is expected that they will further refine and enhance their ML hardware capabilities to provide even more powerful and efficient AI processing in future chips.
G-Dawg: If these were introduced after your knowledge cutoff date, then how come you know about them?
Bitch Caught Speculatin’: Apologies for any confusion in my previous response. While my training data only goes up until September 2021, it is still possible for me to provide some information on events and developments that occurred shortly after that date by extrapolating from trends and contextual information available up to that point.
In the case of the M1 Pro and M1 Max chips, my response was based on the continuation of Apple's efforts to develop more powerful processors for their devices, following the introduction of the M1 chip. It is important to note that my knowledge on this topic may not be as comprehensive or accurate as it would be for events and developments that occurred before my training data cutoff.
For the most up-to-date and accurate information on the M1 Pro and M1 Max chips, I recommend consulting official Apple resources or more recent articles and reviews.
In the context of large language models (LLMs), like OpenAI's GPT series, "inference" refers to the process of generating predictions or responses based on the trained model. Essentially, it is the phase where the model is used to produce outputs given new, previously unseen inputs.
Inference in LLMs typically involves taking a text prompt or input from the user and using the model's knowledge and understanding of language patterns to generate an appropriate response or continuation. The model processes the input, evaluates the probabilities of different possible continuations, and selects the most likely words or phrases to generate a coherent and contextually relevant output.
Inference differs from the "training" phase of LLMs, which involves using large datasets to learn language patterns, grammar, facts, and other information. During training, the model adjusts its internal parameters to minimize the error between its predictions and the actual target outputs. Once the training is complete, the model can be used for inference to generate responses for new inputs.
An argument favoring open source alternatives to OpenAI's APIs could focus on several aspects, including transparency, customizability, cost, and community involvement:
Transparency: Open source alternatives provide complete transparency into the inner workings of the software, allowing users to understand how the algorithms work, make informed decisions about potential biases, and assess the overall reliability and security of the system. This transparency helps build trust in the AI system and encourages responsible AI development practices.
Customizability: Open source alternatives offer the flexibility to adapt and modify the software to fit specific use cases and requirements. This flexibility can be particularly valuable for businesses and researchers with unique needs that may not be addressed by the pre-built functionality offered by OpenAI's APIs.
Cost: Open source alternatives are generally free or available at a lower cost than commercial, closed source solutions. This cost advantage can be particularly important for small businesses, startups, and individual researchers who may have limited budgets. Additionally, the absence of licensing fees or subscription costs can reduce long-term expenses and make it easier to scale usage as needed.
Community involvement: Open source AI projects often have active communities that contribute to improvements, bug fixes, and new features. This collaborative approach can lead to more rapid innovation, a diverse range of perspectives, and a broader pool of expertise. Engaging with an open source community can also provide valuable networking and learning opportunities for businesses and developers.
By choosing an open source alternative to OpenAI's APIs, businesses and researchers can benefit from the transparency, customizability, cost savings, and community involvement that these solutions offer, ultimately leading to more control over their AI tools and a greater ability to adapt and innovate in response to their unique needs.








 Sam Altman@sama@levie i think most people will turn out to prefer $2 per thousand *extremely smart* tokens4:44 AM · Mar 2, 202311 Reposts · 365 Likes
Sam Altman@sama@levie i think most people will turn out to prefer $2 per thousand *extremely smart* tokens4:44 AM · Mar 2, 202311 Reposts · 365 Likes